A News Aggregator to Feed Your Focus
Deep dive into topics and discover new insights
Get started Login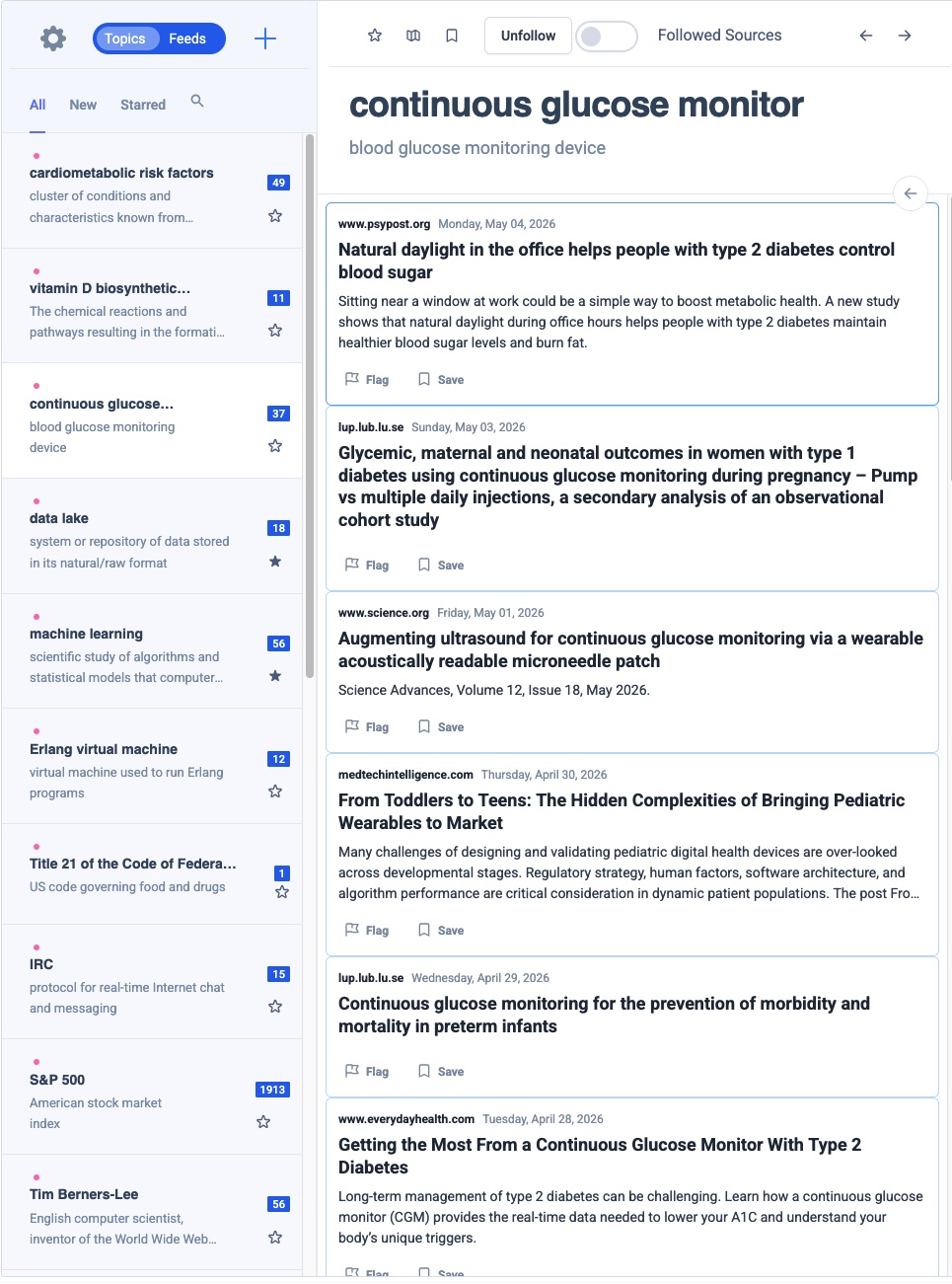
Aggregate Knowledge Across The Web
High-signal streams aggregated and organized by topics from across the web
Topic Streams
Feeds are generated by topic to sift through noise versus signal. Consuming news from multiple sources feels like drinking from a fire-hose. With topic based feeds you can focus on what's important to you.
Deep Dive into Topics
Topic streams allow you to go deep, having contextual awareness helps in zooming in/out to get better understanding of a topic
Discovery Simplified
Discover diverse and global perspective on the topic of your interest providing you viewpoints from different regions and industries helping you broaden your perspective
Collaborate on Topics
Canonical topics makes it possible for people across the web to collaborate and build a collective knowledge base
See How Professionals In Different Fields Are Benefiting
In a knowledge economy, information is the primary currency. Most web tools offer information that is broad and not deep. Topic streams help professionals go deeper into a topic by having the ability to explore the wider context around it.
Policy Professionals
Topic streams from Verified Sources helps in staying factually grounded
Journalists
Predictive reporting allowing journalists to be the first to explain why a crisis is about to happen
Politically Engaged Citizens
Develop actual knowledge with facts rather than just perceived knowledge based out of opinion
Finance and business professionals
Keep on top of competitive and regulatory knowledge
Marketing Professionals
Track trend prediction and influencer
Researchers
Gap identification to spot unexplored niches
Consultants
Synthesize events for client in real-time to show what it means for them
Technology Professionals
Monitor specific changes and policy updates.
Sport Enthusiasts
Keep informed about their team or player off the field
Historians
Monitor digital footprint of specific artificats
Science Professionals
Keep informed about the area of research and cross-polinate with other fields
Hobbyists and DIY'ers
Stay informed and learn new tricks from other hobbyists
730k+ topics indexed and counting
730k+ topics indexed across 3.7m articles and thousands of new topics are indexed every single day